研究人员提出多语言模型优化方法,利用不平衡特性提升多语言能力
近年来,大模型在自然语言处理领域取得了显著进展,尤其在英语、中文等主导语言的任务上表现尤为突出。
然而,这些模型在非主导语言上的能力提升却一直面临瓶颈,导致多语言模型的应用场景受限。
现有的解决方案大多依赖增加高质量多语言数据或通过跨语言对齐来提升非主导语言的表现,这些方法存在成本高昂、数据获取困难、受限于主导语言性能上限等挑战。
为解决这一问题,来自中国科学院自动化研究所的研究团队首次探索利用语言不平衡作为先验偏好,来驱动模型进行多语言的自我提升。
通过一系列的迭代优化,他们不仅有效提升了非主导语言的表现,还在主导语言上实现了性能提升,开创了一种多语言自我优化的新范式。
研究人员表示:“我们期望通过这一方法为多语言大模型领域带来新的视角,塑造‘语言不平衡不仅是问题和挑战也是可学习利用的先验偏好’这一观念。”
同时,他们还希望该思路能够激发更多关于多语言自我优化的探索,推动更均衡、更强大的语言模型发展。
日前,相关论文以《语言不平衡驱动的多语言自我改进的奖励》(Language Imbalance Driven Rewarding for Multilingual Self-improving)为题发在 arXiv[1]。

图 | 相关论文(来源:arXiv)
中国科学院自动化研究所的杨文和武俊宏是共同一作,王晨是合作作者之一。指导老师为该所的张家俊研究员和宗成庆研究员,张家俊研究员担任通讯作者。

提出语言不平衡驱动的奖励机制
据研究人员介绍,当前的多语言大模型在训练过程中,通常依赖于大量的英文或中文等主导语言数据,这导致这些模型在非主导语言上的表现远逊于主导语言。
而在全球化的应用场景中,尤其是面向非主导语言的任务场景中,这种性能差异带来了较大的用户体验不均衡问题。
为了解决这一问题,本次研究提出了一种全新的优化机制,即语言不平衡驱动的奖励机制。
与以往单纯增加多语言数据或跨语言对齐的方法不同的是,该方法利用模型本身在主导语言和非主导语言上的性能差异,将该先验偏好转化为训练的奖励信号,通过迭代训练的方式能够逐步提升模型在不同语言上的表现。
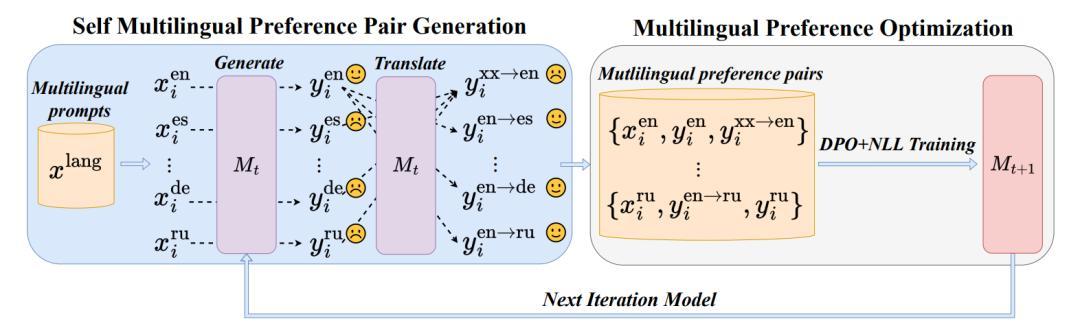
图|语言不平衡驱动的自我优化机制框架图(来源:arXiv)
这一方法主要具备三大创新点:
其一,语言不平衡驱动的奖励信号。
本次研究以一种全新的视角将模型在主导语言和非主导语言表现上的差异转化为奖励信号,使得模型在迭代训练中可以同时优化主导语言和非主导语言的性能。
相比传统的跨语言对齐方法,该方法通过内生的语言不平衡,消除了对大量人工标注数据的依赖,且有效突破了主导语言的性能上限。
其二,迭代直接偏好优化(Iterative Direct Preference Optimization)。
即该方法采用了基于 DPO(Direct Preference Optimization)的优化算法,模型在每轮迭代中生成多语言回复,并通过自我翻译保持语言偏好排名,从而生成用于下一轮训练的偏好数据集。
DPO 通过结合负对数似然损失函数,则能有效提高模型的对齐性能和多语言能力。
其三,自我优化。
本次方法通过自我翻译和偏好对比优化,逐步实现多语言模型的自我提升。
在模型的每轮迭代中,不仅能够有效提升非主导语言的表现,还在主导语言上实现了性能提升,开创了一种多语言自我优化的新范式。
为了验证这一方法的有效性,课题组使用 Meta-Llama-3-8B-Instruct 模型作为实验基准,并在指令跟随任务和数学推理任务上进行了测试。
实验结果显示,在提升非主导语言表现的同时,主导语言(如英语)的性能也得到了显著提升。
例如,在第一次迭代后,英语的性能提升了 15.3%,并在第二轮迭代中能够继续提升。
这证明模型不仅能优化非主导语言,还能通过这种机制突破主导语言的性能瓶颈,进一步推动模型的自我优化。

图 2 | 迭代过程中模型的胜率比较(来源:arXiv)
同时,本次方法通过多轮迭代训练,让模型的多语言能力获得了显著提升,特别是在英语、西班牙语、俄语、德语、法语等 5 种语言的测试中,平均提升了 7.46%。
这展示了本次方法的广泛适用性以及在主导语言和非主导语言之间的同步提升能力。
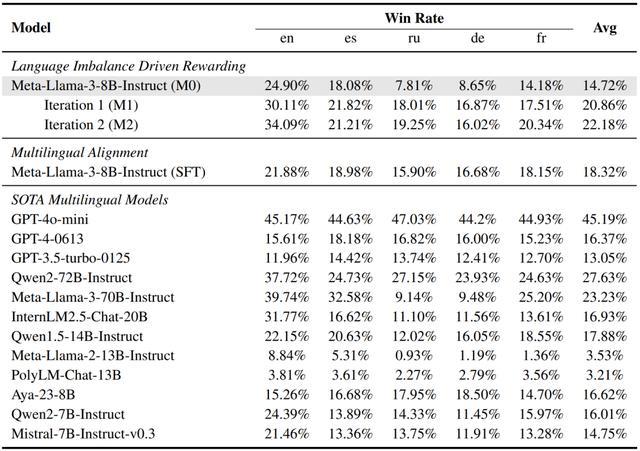
表 4 | X-AlpacaEval 排行榜(来源:arXiv)
在多语言模型训练中,该团队还分析了奖励信号强度的迭代变化。对于训练语言(如英语、法语等),除英语外的高奖励语言在首次迭代后逐渐转为低奖励状态,从而能够推动模型的自我优化。
对于模型训练过程中未出现的语言,意大利语的奖励准确度随英语能力提升而上升,而 DPO 训练中的偏好(如减少脱靶回复)则在日语上表现突出,导致首次迭代之后的日语奖励准确度下降。
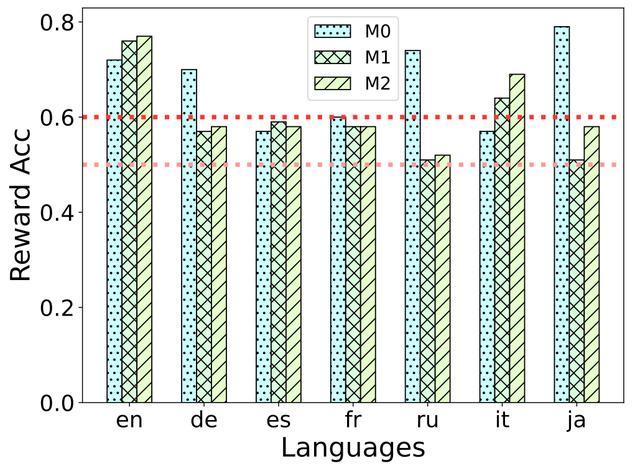
图 3 | 奖励信号随模型迭代的变化(来源:arXiv)
在数学推理基准测试中,模型的整体准确率提升了 13.9%,尤其是在非主导语言上的推理能力得到了显著加强。
实验结果表明,该方法不仅在多语言指令跟随任务上表现优异,在复杂的推理任务中也有良好的表现。
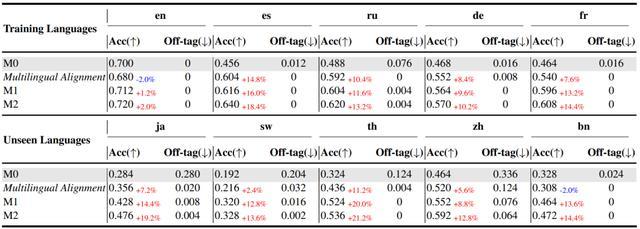
表 5 | 多语言数学推理基准测试的性能(来源:arXiv)
总的来说,本次研究提出了“语言不平衡驱动的奖励模型”,通过利用主导语言和非主导语言之间的内在不平衡,能够持续优化大模型的多语言能力。
经过两轮的迭代训练之后,实验结果显示非主导语言(如德语、俄语等)的表现显著提升,而主导语言(如英语)的性能也得到了同步改善。
这证明自我改进机制可以有效促进多语言模型在各语言间的平衡发展,且无需依赖人工标注数据。
研究人员表示:“该研究不仅为多语言模型的自我改进提供了新的思路,还展现了模型在语言内部优化和自我提升方面的潜力。”
未来,他们计划探索更精细的奖励信号,以便提高多语言自我改进的效率。同时,其也会继续优化翻译质量,减少翻译过程中的误差,进一步提升回复质量。
目前,本次项目的代码已经在 GitHub 开源(项目地址:https://github.com/ZNLP/Language-Imbalance-Driven-Rewarding)。
随着这项方法的不断优化,该团队相信未来的多语言大模型将能够以更高效、更包容的方式,应对来自世界各地的语言需求,推动人工智能技术在全球的普及与应用。
运营/排版:何晨龙